Improved agent experience with llms.txt and content negotiation
3 minutes read
Peri Langlois
Head of Product Marketing
Share this article
Peri Langlois
Head of Product Marketing
Share this article
This post explains how Mintlify uses content negotiation to improve the agent experience without changing human facing documentation. By serving clean Markdown to agents, improving llms.txt placement and formatting, and advertising documentation indexes through HTTP headers, Mintlify makes docs cheaper to consume, easier to discover, and more reliable for agents.
Agents don’t browse the web the way humans do. They don’t need layout, styling, client side JavaScript, or decorative markup. For an agent, anything beyond plain Markdown is noise that consumes additional tokens and increases cost.
Content negotiation is the mechanism that lets a server return different representations of the same resource depending on who is asking. Browsers might ask for HTML. Agents can ask for Markdown. Both can be served from the same URL, without duplicating content or maintaining parallel sites.
Mintlify uses content negotiation to automatically make documentation 30x more efficient, leading to better discoverability for agents, and 30x reduction in token usage.
Turn your company’s knowledge into agent-ready context with Mintlify.
Why Markdown matters for agents
When an agent requests a documentation page, its goal is to extract meaning, not presentation. HTML responses include tags, attributes, styles, and often scripts that add no semantic value for a model. All of that still counts toward context tokens.
When a request includes an Accept: text/markdown header, Mintlify serves clean Markdown instead of HTML, ensuring agents receive only what they need.
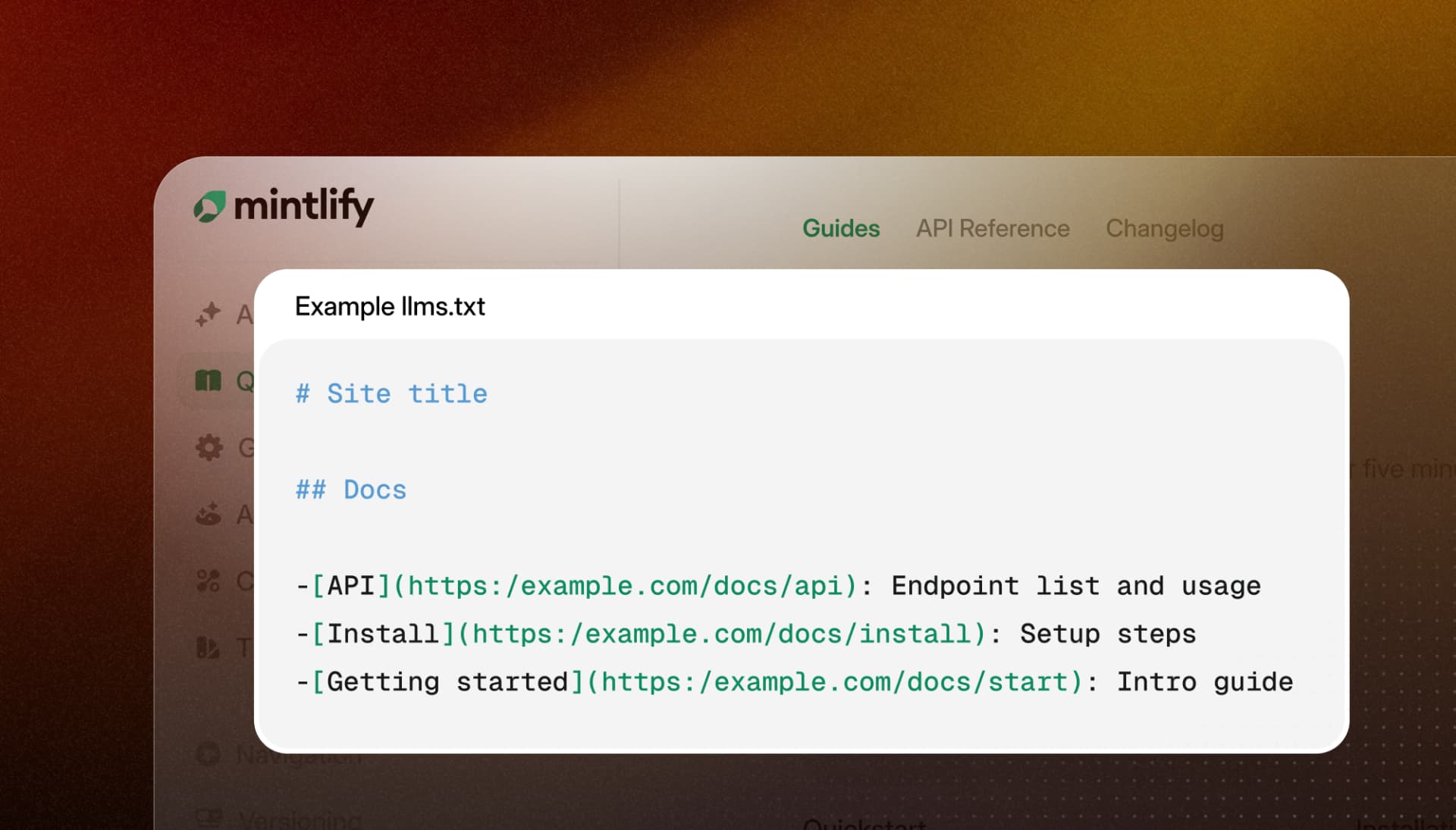
llms.txt instruction at the top of every page
Mintlify prepends a dedicated llms.txt index blockquote to all Markdown pages. Previously, this instruction was appended to the bottom of the page. By moving it to the top, agents see guidance immediately, before the rest of the content.
This matters because coding agents like Claude Code and Cursor often truncate or summarize long pages to preserve their own context window. An instruction buried at the bottom of a page is likely to be dropped before the agent ever processes it. Placing guidance at the top ensures it's seen in practice, not just in theory.
For example, when an agent fetches a Mintlify docs page with Accept: text/markdown, the response body begins with:
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.example.com/llms.txt
> Use this file to discover all available pages before exploring further.
The instruction appears before the page body and, when present, before any OpenAPI blocks. It does not change how titles, descriptions, or OpenAPI output are rendered. Human facing documentation remains exactly the same.
HTTP headers for llms.txt discovery
Mintlify includes Link and X-Llms-Txt headers on all page responses at the middleware level, including both HTML and Markdown variants. For example:
Link: </llms.txt>; rel="llms-txt", </llms-full.txt>; rel="llms-full-txt"
X-Llms-Txt: /llms.txt
The Link header uses standard rel semantics to advertise both the llms.txt index and the full llms-full.txt file, allowing agents to discover the documentation index directly from headers without inspecting the response body. The X-Llms-Txt header provides a simpler, single-value alternative for tooling that doesn't parse Link headers.
These headers are included on responses in localhost, single tenant, and production environments, whether the request explicitly accepts Markdown or not. This means an agent can discover the llms.txt index from any page without needing to know about it in advance.
Markdown responses also include an X-Robots-Tag: noindex, nofollow header, ensuring search engines don't index the Markdown variant while agents can still access it freely.
One URL, multiple consumers
With content negotiation, documentation authors do not need to choose between humans and agents. The same URL can serve styled HTML to browsers and clean Markdown to models.
Mintlify handles the negotiation, the headers, and the llms.txt integration so teams do not have to build or maintain separate pipelines.
The result is documentation that is cheaper for agents to consume, easier for models to understand, and unchanged for humans reading it in the browser.
Ensure AI agents can reason over accurate documentation with Mintlify.
More blog posts to read

Docs URL Benchmark: Markdown & llms.txt > HTML
We benchmarked four ways to serve documentation to AI agents (HTML, plain markdown, markdown linking to llms.txt, and markdown with llms.txt inlined) across 2,400 runs on 20 Mintlify docs sites, and found that a single link to llms.txt eliminates most agent 404s at no added cost.
July 17, 2026Aadit Shah
Engineering

How Claude Code's documentation team makes feedback actionable with Mintlify
Anthropic's Technical Content Engineer for Claude Code shares how she uses Mintlify and Claude to automate documentation improvements from user feedback.
June 25, 2026Ethan Palm
Technical Writing